
About this project
Upon reading that some police departments were beginning to roll out tools to create suggested composite photographs of perps from police sketches, my team was immediately curious as to how dramatic the effects of biased data sets could skew the perception of a person's identity. We explored this project in 3 phases: - Interpreting the visual signals of a sketch: human drawing vs. computer drawing - Creating ostensible composite photo renderings from sketched inputs - Comparing the effects of biased data sets on the same input sketch
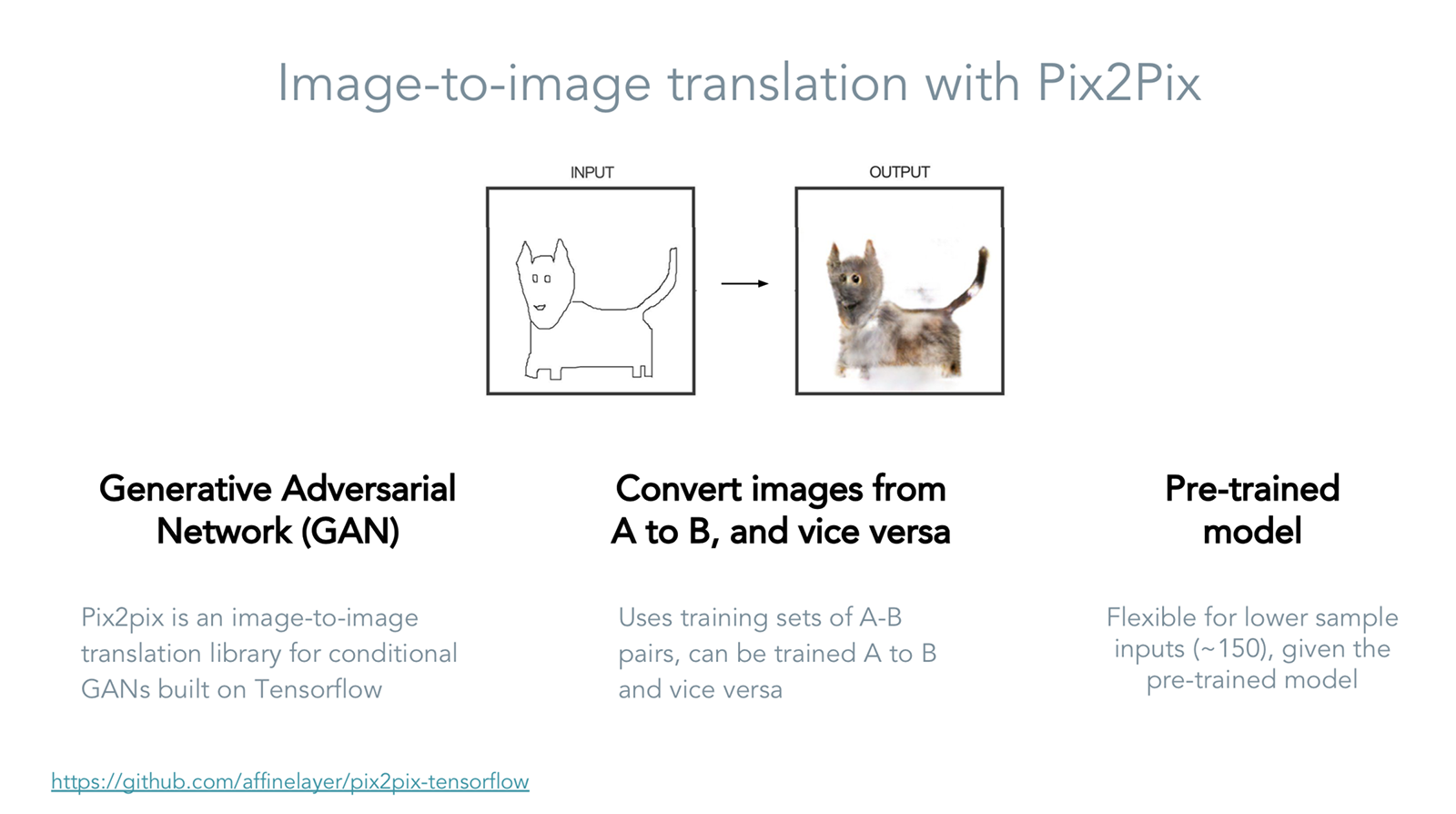
Using Pix2Pix and TensorFlow to train our model
Face2Race uses a Pix2pix, a pre-trained generative adversarial network (GAN) built with Tensorflow, to teach our model how to interpret racial characteristics from sketched visual inputs. Through machine learning, Pix2Pix can continuously test and improve its concept of how to produce an output image based on the set of input images. It can be used to do things like fill in images of cats, continue drawings, produce accurately colored images, and more.

User Testing
To explore how racial characteristics were manifested in human sketches, we ran a user study with 7 artists of varying artistic experience and gave each participant 10 seconds to view an image, followed by 30 seconds to draw the person from memory.
Digital "sketching" process
While we had human sketches as an input, we needed to quickly generate hundreds of "sketches" that we could train our model of actual human faces against. (Because Pix2Pix is already pre-trained, we didn't need as much training data as is typically used for GANs.) To assist in this, we ran a Photoshop script to digitally render "sketches" -- a form of a computer's interpretation of a human face, in a way.
The GAN creates a "filled" version of the model based on the human sketches.
We ran the human input sketches against models that were designed to be intentionally biased to expose the biggest phenotypical differences:
- 100% of a single ethnicity (black, white, Asian, Hispanic)
- 25% (equally split)
- Proportional to the U.S. population
- Proportional to the US Congress
Results of equalized model
The equalized model is telling, and effectively turns any input race into the beige/caramel-y mixed race individual of the future.

Model Bias
The project was designed to visualize the phenotypical effects of a biased data set. To expose the most dramatic differences, we designed a number of biased data sets at different levels of homogeneity. The most dramatic examples come from exposing an individual of one race (e.g. Asian) to a model biased 100% for another race (e.g. white).
Who's in the Machine?
The project hopes to provoke critical examination of the sources of data and underlying biases behind algorithms and machine learning predictions as they become more prevalent in every day life. In disproportionately unbalanced populations, such as among U.S. politicians, Silicon Valley engineers, or incarcerated populations, underlying data sets could be entirely skewed by natural biases while lay users might assume an inherent equality. These "weapons of math destruction" have already been shaking up everything from hiring to criminal justice reform, but the conversations around design and data ethics is only in nascent stages. As designers increasingly called to make active decisions in our products and applications, what role will we have in defining the ethics of data use?